
Обход веб-сайтов и сбор данных – это процесс, требующий большого объема памяти. Чем больше вы сканируете, тем больше памяти нужно для хранения и обработки данных. В Screaming Frog SEO Spider используется настраиваемый гибридный движок, который требует некоторых настроек для крупномасштабного сканирования.
По умолчанию SEO Spider использует оперативную память, а не жесткий диск для хранения и обработки данных. Это обеспечивает удивительные преимущества, такие как скорость и гибкость, но здесь также есть недостатки, в особенности при масштабном сканировании.
SEO Spider можно настроить для сохранения данных сканирования на диск, выбрав режим «Database Storage» (в разделе «Configuration > System > Storage»), который позволяет сканировать данные в действительно беспрецедентном масштабе, сохраняя при этом те же знакомые отчеты в реальном времени и удобство использования.
Если вы не хотите читать полное руководство ниже, приведем два основных требования для сканирования очень больших веб-сайтов.
1) Используйте компьютер с внутренним SSD и переключитесь в режим хранения в базе данных («Configuration > System > Storage»).

2) Выделите ОЗУ («Configuration > System > Storage»). 8 Гб достаточно для сканирования примерно 5 миллионов URL.
В приведенном ниже руководстве представлен более полный обзор различий между хранением в памяти и в базе данных, идеальных настроек для сканирования больших веб-сайтов и способов интеллектуального сканирования, чтобы избежать ненужной траты времени и ресурсов.
- Каковы различия между памятью и базой данных?
- Хранение в памяти
- Хранение в базе данных
- Вам действительно нужно сканировать весь сайт?
- 1) Переключиться на хранилище в базе данных
- 2) Увеличить выделение памяти
- 3) Настроить, что конкретно сканировать
- 4) Исключить ненужные URL
- 5) Сканировать в разделах (поддомен или подпапки)
- 6) Сузить сканирование, используя «Include»
- 7) Ограничить сканирование для лучшей выборки
- 8) Купить внешний SSD с USB 3.0 (или аналог)
- 9) Запустить SEO Spider в облаке с SSD и большим количеством оперативной памяти
- 10) Не забывайте регулярно сохранять
Каковы различия между памятью и базой данных?
По сути, оба способа хранения обеспечивают практически одинаковое сканирование, позволяя создавать отчеты, фильтровать и настраивать сканирование в режиме реального времени. Однако существуют некоторые ключевые различия. Идеальное хранилище зависит от сценария сканирования и технических характеристик компьютера.
Хранение в памяти
Этот режим позволяет осуществлять сверхбыстрое и гибкое сканирование практически для всех настроек. Однако оперативной памяти в компьютерах меньше, чем пространства на жестком диске. Это означает, что SEO Spider больше подходит для сканирования сайтов в режиме хранения в памяти, если там до 500 тысяч URL-адресов.
При правильных настройках можно сканировать и больше. Все зависит от того, насколько интенсивно сайт потребляет память. Например, 64-битный компьютер с 8 Гб оперативной памяти, как правило, позволяет сканировать пару сотен тысяч URL-адресов.
Помимо того, что это лучший вариант для небольших веб-сайтов, режим хранения в памяти также рекомендуется для компьютеров без SSD или в случаях, когда недостаточно места на диске.
Хранение в базе данных
Мы рекомендуем использовать ее как хранилище по умолчанию пользователям с SSD и для масштабного сканирования. Режим хранения в базе данных позволяет сканировать больше URL-адресов, при этом скорость будет практически такой же, как при хранении в памяти.
Ограничение сканирования по умолчанию составляет 5 миллионов URL-адресов, но оно не жесткое – SEO Spider способен сканировать значительно больше (при правильной настройке). Например, компьютер с SSD на 500 Гб и 16 Гб ОЗУ должен позволять вам сканировать приблизительно до 10 миллионов URL-адресов.
В режиме хранения базы данных результаты сканирования также автоматически сохраняются, поэтому нет необходимости «сохранять» их вручную. Другое главное преимущество заключается в том, что повторное открытие сохраненного результата сканирования намного быстрее, чем загрузка файла .seospider в режиме хранения в памяти.
Сканирование базы данных осуществляется с помощью «File > Crawls»:

Меню «Crawls» отображает обзор сохраненных сканирований, позволяет открывать их, переименовывать, организовывать в папки проекта, дублировать, экспортировать или массово удалять.

Дополнительным преимуществом является то, что, поскольку результат обхода автоматически сохраняется, то в случае возникновения проблемы (отключение питания или сбой) он должен быть восстановлен из меню «Crawls».
Хотя это и не рекомендуется, но если у вас быстрый HDD, а не SSD, этот режим все же может позволить вам сканировать много URL-адресов. Однако скорость записи и чтения жесткого диска могут повлиять на то, что и скорость сканирования, и сам интерфейс будут значительно медленнее.
Если вы работаете на компьютере во время сканирования, это также может повлиять на производительность. Поэтому может потребоваться уменьшить скорость сканирования, чтобы справиться с нагрузкой. SSD настолько быстры, что у них, как правило, нет этой проблемы. По этой причине хранение в базе данных может использоваться по умолчанию как для малых, так и для больших объемов сканирования.
Вам действительно нужно сканировать весь сайт?
Это вопрос, который мы всегда рекомендуем задавать. Вам нужно сканировать каждый URL, чтобы получить требуемые данные?
Опытные оптимизаторы знают, что часто это просто не требуется. Как правило, веб-сайты являются шаблонными, и выборочного сканирования типов страниц из разных разделов будет достаточно для принятия обоснованных решений по более обширным сайтам.
Итак, зачем сканировать 5 миллионов URL, когда достаточно 50 тысяч? С помощью нескольких простых настроек вы можете избежать затрат ресурсов и времени на них.
Стоит помнить, что сканирование больших сайтов требует ресурсов, много времени (и затрат на некоторые решения). Веб-сайт на 1 миллион страниц со средней скоростью сканирования 5 URL-адресов в секунду будет сканироваться в течение двух дней. Вы можете сканировать быстрее, но большинство веб-сайтов и серверов не поддерживают более быстрое сканирование.
При рассмотрении масштаба необходимо учитывать не только уникальные страницы или собранные данные, но и фактически внутренние ссылки на веб-сайт. SEO Spider записывает каждую отдельную входящую или исходящую ссылку (и ресурс). Это означает, что сайт на 100 тысяч страниц, содержащий по 100 ссылок на каждой, в общей сложности содержит более 10 миллионов ссылок.
Однако, с учетом вышесказанного, бывают случаи, когда полный обход необходим. Возможно, вам придется сканировать большой веб-сайт целиком, иногда он находится на корпоративном уровне с 50-миллионными страницами, и вам нужно сканировать больше, чтобы получить точный образец. В этих случаях мы рекомендуем следующий подход для сканирования больших веб-сайтов.
1) Переключиться на хранилище в базе данных
Мы советуем использовать SSD и перейти в режим хранения в базе данных. Если у вас нет SSD, мы настоятельно рекомендуем его купить. Это единственное крупнейшее обновление, которое вы можете сделать для компьютера при сравнительно небольших затратах. Оно позволит сканировать в огромных масштабах без ущерба для производительности.
Пользователи могут выбрать сохранение на диск, отметив «Режим хранения в базе данных» в интерфейсе (через «Configuration > System > Storage»).

Если у вас нет SSD, можете проигнорировать этот шаг и просто следовать остальным рекомендациям в руководстве. Стоит отметить, что вы можете использовать внешний SSD с USB 3.0, если система поддерживает режим UASP.
2) Увеличить выделение памяти
SEO Spider стандартно выделяет всего 1 Гб ОЗУ для 32-битных компьютеров и 2 Гб ОЗУ для 64-битных. В режиме хранения в памяти это должно позволить вам сканировать 10-150 тысяч URL-адресов веб-сайта. В режиме хранения в базе данных вы сможете сканировать примерно 1-2 миллиона URL-адресов.
Объем выделенной оперативной памяти будет влиять на количество URL-адресов, которые вы можете сканировать при хранении в памяти или в базе данных. В первом случае это влияние гораздо более существенно.
В режиме хранения в ОЗУ мы рекомендуем минимум 8 Гб ОЗУ для сканирования больших веб-сайтов с несколькими сотнями тысяч страниц. Но чем больше у вас оперативной памяти, тем лучше.
При хранении в базе данных 8 Гб ОЗУ позволят сканировать до 5 миллионов URL-адресов, 16 Гб – до 10 миллионов и 32 Гб ОЗУ – более 20 миллионов URL-адресов. Эти данные приблизительные, так как все зависит от сайта.
В режиме хранения в базе данных SEO Spider сохранит информацию на диск, когда использует весь выделенный объем памяти. Если вы хотите сохранить данные раньше, выделите меньше оперативной памяти.
Вы можете настроить распределение памяти в SEO Spider, нажав «Configuration > System > Memory».
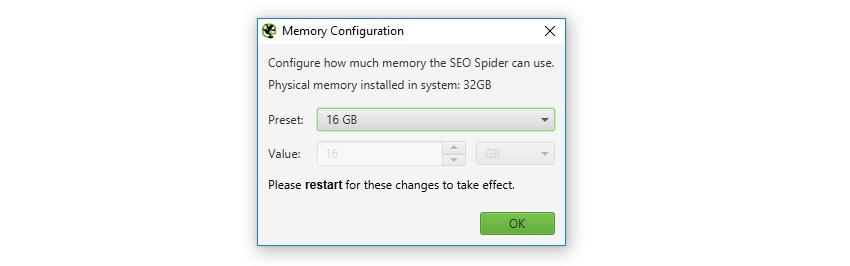
Мы всегда рекомендуем выделять как минимум на 2 Гб меньше общей доступной оперативной памяти. Если вы выделите общий объем ОЗУ, вы можете столкнуться со сбоем, поскольку вашей операционной системе и другим приложениям также требуется ОЗУ для работы.
SEO Spider использует память только тогда, когда это необходимо. Вам всегда доступен максимальный объем.
Если вы не настроили память и не достигли предела ее выделения, вы получите следующее предупреждение:

Это значит, что SEO Spider достиг текущего объема памяти и его нужно увеличить, чтобы сканировать больше URL-адресов, иначе он станет нестабильным.
Для увеличения памяти вы должны сохранить сканирование через меню «File > Save». Затем можно настроить распределение памяти, открыть сохраненный результат обхода и возобновить сканирование еще раз.
Чем больше памяти вы выделите, тем больше вы сможете сканировать. Поэтому, если у вас нет компьютера с большим объемом оперативной памяти, мы рекомендуем использовать более мощную технику или увеличить объем оперативной памяти.
3) Настроить, что конкретно сканировать
Чем больше данных будет собрано и чем больше будет сканироваться, тем интенсивнее использование памяти. Но есть варианты снижения потребления памяти для более легкого сканирования.
Отмена выбора следующих параметров в разделе «Configuration > Spider> Crawl» поможет сэкономить память. Проверьте:
- Crawl & Store Images;
- Crawl & Store CSS;
- Crawl & Store JavaScript;
- Crawl & Store SWF;
- внешние ссылки.
Обратите внимание: если вы сканируете в режиме рендеринга JavaScript, вам, вероятно, понадобится включить большинство этих опций, иначе это повлияет на рендер.
Вы также можете отменить выбор следующих параметров сканирования в разделе «Configuration > Spider», чтобы сэкономить память:
- Crawl & Store External Links;
- Crawl & Store Canonicals;
- Crawl & Store Pagination;
- Crawl & Store Hreflang;
- Crawl & Store AMP.
Вы можете отменить сканирование незначительных атрибутов, хранящихся в в разделе «Configuration > Spider> Extraction», например сканирование Meta Keywords:
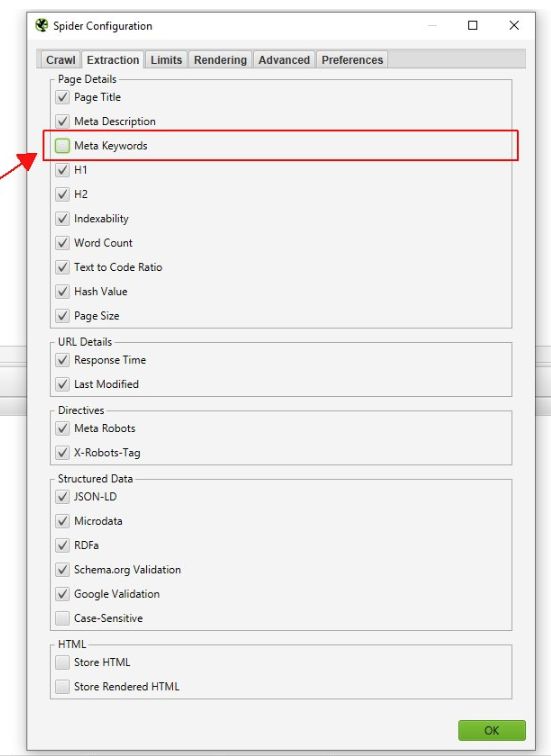
Есть также другие варианты, которые будут потреблять память, если она задействуется, поэтому не используйте следующие функции:
- Custom Search;
- Custom Extraction;
- Google Analytics Integration;
- Google Search Console Integration;
- PageSpeed Insights Integration;
- Link Metrics Integration (Majestic, Ahrefs and Moz).
Чем меньше данных, тем меньше сканирования и потребление памяти.
4) Исключить ненужные URL
Используйте функцию исключения, чтобы избежать сканирования ненужных URL-адресов. Это могут быть целые разделы, фасетные навигационные фильтры, конкретные параметры URL-адресов или бесконечные URL-адреса с повторяющимися каталогами и т. д.
Функция исключения позволяет полностью убрать URL-адреса из сканирования, предоставляя список регулярных выражений. URL-адрес, соответствующий исключению, вообще не сканируется (он не просто «скрыт» в интерфейсе). Другие URL-адреса, которые не соответствуют исключению, но доступны только с исключенной страницы, также не будут сканироваться. Так что используйте эту функцию с осторожностью.
Мы рекомендуем выполнить сканирование и упорядочить URL-адреса на вкладке «Internal» в алфавитном порядке, а также проанализировать их на предмет наличия шаблонов и областей для потенциального исключения в режиме реального времени. Как правило, прокручивая и анализируя URL-адреса, вы можете составить список для исключения.
Например, сайты интернет-магазинов часто имеют фасетные навигации, которые позволяют пользователям фильтровать и сортировать, что может привести к увеличению количества URL при сканировании. Иногда их можно сканировать в другом порядке, что также приводит ко множеству или бесконечному количеству URL.
Рассмотрим пример из реальной жизни – www.johnlewis.com. Если вы сканируете сайт со стандартными настройками, из-за многочисленных аспектов вы можете легко сканировать отфильтрованные страницы, как показано ниже.

При выборе этих аспектов создаются URL-адреса, например:
https://www.johnlewis.com/browse/men/mens-trousers/adidas/allsaints/gant-rugger/hymn/kin-by-john-lewis/selected-femme/homme/size=36r/_/N- ebiZ1z13yvxZ1z0g0g6Z1z04nruZ1z0s0laZ1z13u9cZ1z01kl3Z1z0swk1
В URL отображены несколько брендов, размер брюк и выбранный вариант доставки. Есть также аспекты для цвета, подгонка брюк и многое другое. Различное количество комбинаций, которые могут быть выбраны, практически бесконечно, и их следует учитывать для исключения.
Упорядочив URL-адреса на вкладке «Internal» в алфавитном порядке, можно легко определить подобные шаблоны URL для потенциального исключения. Указанные для примера URL-адреса в любом случае имеют значение «noindex». Следовательно, мы можем просто исключить их из сканирования.

После получения образца URL-адресов и определения проблемы обычно нет необходимости сканировать каждый аспект и комбинацию. Они также могут быть уже канонизированы, запрещены или закрыты от индексации, то есть их можно просто исключить.
5) Сканировать в разделах (поддомен или подпапки)
Если веб-сайт очень большой, вы можете рассмотреть его по разделам. По умолчанию SEO Spider сканирует только введенный поддомен, а все остальные обнаруженные поддомены будут рассматриваться как внешние (отображаются на вкладке «External»). Вы можете выбрать обход всех поддоменов, но потребуется больше памяти.
SEO Spider также можно настроить для сканирования подпапки, просто введя ее URL с путем к файлу и убедившись, что в «Configuration > Spider» не выбрано «Check links outside of start folder» и «Crawl outside of start folder». Например, чтобы сканировать блог SF, вам нужно ввести https://www.screamingfrog.co.uk/blog/ и нажать «Start».
Обратите внимание: если в конце подпапки нет косой черты, например «/blog» вместо «/blog/», SEO Spider в настоящее время не распознает ее как подпапку и не сканирует ее. Если версия вложенной косой черты в подпапке перенаправляется на версию без косой черты, то применяется то же самое.
Чтобы сканировать эту подпапку, вам нужно использовать функцию включения и ввести регулярное выражение этой подпапки (в этом примере – .*blog.*).
6) Сузить сканирование, используя «Include»
Вы можете использовать функцию включения, чтобы контролировать, какой URL-путь будет сканировать SEO Spider через регулярное выражение. Он сужает поиск по умолчанию, сканируя только те URL-адреса, которые соответствуют регулярному выражению, что особенно полезно для крупных сайтов или сайтов с менее интуитивно понятными структурами URL-адресов.
Соответствие выполняется на URL-кодированной версии адреса. Страница, с которой вы запускаете сканирование, должна иметь исходящую ссылку, соответствующую регулярному выражению, чтобы функция работала. Если на стартовой странице нет URL, соответствующего регулярному выражению, SEO Spider не будет ничего сканировать.
Например, если вы хотите сканировать страницы из https://www.screamingfrog.co.uk, которые имеют «Search» в строке URL, укажите «.*Search.*» в вкладке «Include».

Это позволит найти страницы /search-engine-marketing/ и / search-engine-optimisation/, так как в них есть «search».

Больше возможностей для исключения страниц было рассмотрено в данной статье, в пункте 5.
7) Ограничить сканирование для лучшей выборки
Доступны различные ограничения, которые помогают контролировать сканирование SEO Spider и позволяют получить образец страниц по сайту, не сканируя все. Они включают:
- Limit Crawl Total – ограничение общего числа сканируемых страниц. Просмотрите сайт, чтобы получить приблизительную оценку того, сколько может потребоваться для сканирования широкого выбора шаблонов и типов страниц.
- Limit Crawl Depth – ограничение глубины сканирования ключевыми страницами. Обеспечивает достаточную глубину, чтобы получить образец всех шаблонов.
- Limit Max URL Length To Crawl – ограничение максимальной длины URL для обхода. Избегайте сканирования некорректных относительных ссылок или очень глубоких URL-адресов, ограничивая длину строки URL-адреса.
- Limit Max Folder Depth – ограничение максимальной глубины папки, что может быть более полезно для сайтов с интуитивно понятными структурами.
- Limit Number of Query Strings – ограничение обхода множества фасетов и параметров по количеству строк запроса. Устанавливая ограничение строки запроса равным «1», вы позволяете SEO Spider сканировать URL-адрес с одним параметром (например,?=colour), но не больше. Это полезно, когда различные параметры могут быть добавлены к URL в разных комбинациях.
8) Купить внешний SSD с USB 3.0 (или аналог)
Если у вас нет внутреннего SSD, а вы хотите сканировать большие веб-сайты в режиме хранения в базе данных, может помочь внешний SSD.
Важно убедиться, что на вашем компьютере есть порт USB 3.0, а система поддерживает режим UASP. Большинство новых систем работают автоматически, если у вас уже есть оборудование USB 3.0. При использовании внешнего SSD убедитесь, что вы подключены к порту USB 3.0, иначе чтение и запись будут очень медленными.
Порты USB 3.0 обычно имеют синий цвет (как рекомендуется в их спецификации), но не всегда. Как правило, потребуется подключить USB-кабель синего цвета к синему порту USB 3.0. После этого нужно переключиться в режим хранения в базе данных, а затем выбрать расположение базы данных на внешнем SSD (диск «D» в приведенном ниже примере).

9) Запустить SEO Spider в облаке с SSD и большим количеством оперативной памяти
Если вам все еще нужно сканировать больше, но у вас нет мощного компьютера с SSD или большим объемом оперативной памяти, подумайте о запуске SEO Spider в облаке и убедитесь, что у него есть SSD. Вы переключитесь в режим «Database storage», выделив достаточный объем оперативной памяти.
Примеры руководств на английском языке:
- – Fili Weise
- – Mike King
10) Не забывайте регулярно сохранять
Если вы устанавливаете лимит памяти для SEO Spider, мы рекомендуем регулярно сохранять проекты сканирования. Если есть проблема, это означает, что вы не потеряете все результаты.
Вы можете сохранить сканирование, нажав «Stop», а затем «File > Save». После завершения сканирования нажмите «Resume», чтобы продолжить сканирование с этого момента.
Если вы используете режим хранения базы данных, тогда вам не о чем беспокоиться. Сканирования автоматически сохраняются, и если у вас возникли проблемы, то сканирование должно быть доступно для возобновления в «File> Crawls».
Надеемся, что вам помогла данная статья, а в следующих переводах блога сайта Screaming Frog постараемся осветить другие полезные темы.








Полезная информация, благодарю.